This article is submitted by my student:
If you want to feature your article, you can kindly contact me via email and send your article submissions (content and the resources). Once they are reviewed, I should accept and post the same 🤗

Anbarasan Ganesan, Chennai, India
2.5+ years of experience in WLAN Device Driver Development and 2+ years of experience in Software Development. Had developed software for ARM micro-controllers. And I have been working in WLAN device driver development and debugging

- Introduction
- RFS Configuration
- Configuration code
- Suggested Configuration
- RFS operational code flow
- Enabling RFS
- Writing into proc entry rps_sock_flow_entries (rps_sock_flow_table)
- Writing into sys entry rps_flow_cnt (rps_dev_flow_table)
- Feature implementation
Introduction:
Application locality is accomplished by Receive Flow Steering (RFS). Thus the goal of RFS is to increase data-cache hitrate by steering kernel processing of packets to the CPU where the application thread consuming the packet is running. RFS relies on the same RPS mechanisms to enqueue packets onto the backlog of another CPU and to wake up that CPU.
RFS Configuration code:
RFS is only available if the kconfig symbol CONFIG_RPS is enabled (on by default for SMP). The functionality remains disabled until explicitly configured.
The number of entries in the global flow table is set through:
1. /proc/sys/net/core/rps_sock_flow_entries
The number of entries in the per-queue flow table are set through:
2. /sys/class/net//queues/rx-/rps_flow_cnt
Configuration code:
Let us see how the proc entry for rps_sock_flow_entries and sys class entry for rps_flow_cnt is created.
1. /proc/sys/net/core/rps_sock_flow_entries
When user enter the rfs flow entries in above proc entry, the corresponding proc handler rps_sock_flow_sysctl is get called. AS shown in the flow chart, sysctl_core_init is registered as part fs_initcall during boot up. Then, proc handler for “rps_sock_flow_entries” created through ctl_table.

Refer Linux Kernel’s /net/core/sysctl_net_core.c
static struct ctl_table net_core_table[] = {
#ifdef CONFIG_NET
...
#ifdef CONFIG_RPS
{
.procname = "rps_sock_flow_entries",
.maxlen = sizeof(int),
.mode = 0644,
.proc_handler = rps_sock_flow_sysctl
},
#endifRefer Linux Kernel’s /include/linux/netdevice.h
/*
* The rps_sock_flow_table contains mappings of flows to the last CPU
* on which they were processed by the application (set in recvmsg).
* Each entry is a 32bit value. Upper part is the high-order bits
* of flow hash, lower part is CPU number.
* rps_cpu_mask is used to partition the space, depending on number of
* possible CPUs : rps_cpu_mask = roundup_pow_of_two(nr_cpu_ids) - 1
* For example, if 64 CPUs are possible, rps_cpu_mask = 0x3f,
* meaning we use 32-6=26 bits for the hash.
*/
struct rps_sock_flow_table {
u32 mask;
u32 ents[0] ____cacheline_aligned_in_smp;
};2. /sys/class/net//queues/rx-/rps_flow_cnt
When user enter the rfs flow count in above sys entry, the function store_rps_dev_flow_table_cnt is get called. This function pointer is initialized as part of kobject_init_and_add() which is added during the register_netdevice(), as shown in the below chart.

static int rx_queue_add_kobjects(struct net_device *dev, int index)
{
error = kobject_init_and_add(kobj, &rx_queue_ktype, NULL,
"rx-%u", index);
}
struct rx_queue_attribute {
struct attribute attr;
ssize_t (*show)(struct netdev_rx_queue *queue,
struct rx_queue_attribute *attr, char *buf);
ssize_t (*store)(struct netdev_rx_queue *queue,
struct rx_queue_attribute *attr, const char *buf, size_t len);
};
static struct rx_queue_attribute rps_cpus_attribute =
__ATTR(rps_cpus, S_IRUGO | S_IWUSR, show_rps_map, store_rps_map);
static struct rx_queue_attribute rps_dev_flow_table_cnt_attribute =
__ATTR(rps_flow_cnt, S_IRUGO | S_IWUSR,
show_rps_dev_flow_table_cnt, store_rps_dev_flow_table_cnt);
static struct attribute *rx_queue_default_attrs[] = {
#ifdef CONFIG_RPS
&rps_cpus_attribute.attr,
&rps_dev_flow_table_cnt_attribute.attr,
#endif
NULL
};
static const struct sysfs_ops rx_queue_sysfs_ops = {
.show = rx_queue_attr_show,
.store = rx_queue_attr_store,
};
static struct kobj_type rx_queue_ktype = {
.sysfs_ops = &rx_queue_sysfs_ops,
.release = rx_queue_release,
.default_attrs = rx_queue_default_attrs,
.namespace = rx_queue_namespace
};Suggested Configuration
Both of these need to be set before RFS is enabled for a receive queue. Values for both are rounded up to the nearest power of two. The suggested flow count depends on the expected number of active connections at any given time, which may be significantly less than the number of open connections. We have found that a value of 32768 for rps_sock_flow_entries works fairly well on a moderately loaded server.
For a single queue device, the rps_flow_cnt value for the single queue would normally be configured to the same value as rps_sock_flow_entries. For a multi-queue device, the rps_flow_cnt for each queue might be configured as rps_sock_flow_entries / N, where N is the number of queues. So for instance, if rps_sock_flow_entries is set to 32768 and there are 16 configured receive queues, rps_flow_cnt for each queue might be configured as 2048.
RFS operational code flow
Let us try to understand how RFS feature is implemented in the kernel.
Enabling RFS By editing below two files, RFS is enabled.
1. /proc/sys/net/core/rps_sock_flow_entries
2. /sys/class/net//queues/rx-/rps_flow_cnt
Writing into proc entry rps_sock_flow_entries
static int rps_sock_flow_sysctl(struct ctl_table *table, int write,
void __user *buffer, size_t *lenp, loff_t *ppos)
{
struct ctl_table tmp = {
.data = &size,
.maxlen = sizeof(size),
.mode = table->mode
};
size = orig_size = orig_sock_table ? orig_sock_table->mask + 1 : 0;
ret = proc_dointvec(&tmp, write, buffer, lenp, ppos);
if (size != orig_size) {
sock_table =
vmalloc(RPS_SOCK_FLOW_TABLE_SIZE(size));
rps_cpu_mask = roundup_pow_of_two(nr_cpu_ids) - 1;
sock_table->mask = size - 1;
}
else
sock_table = orig_sock_table;
for (i = 0; i < size; i++)
sock_table->ents[i] = RPS_NO_CPU
if (sock_table != orig_sock_table) {
rcu_assign_pointer(rps_sock_flow_table, sock_table);
if (sock_table) {
static_key_slow_inc(&rps_needed);
static_key_slow_inc(&rfs_needed);
}
if (orig_sock_table) {
static_key_slow_dec(&rps_needed);
static_key_slow_dec(&rfs_needed);
synchronize_rcu();
vfree(orig_sock_table);
}
}In proc handler rps_sock_flow_sysctl, the table rps_sock_flow_table is dereferenced with corresponding mutex lock held. struct member rps_sock_flow_table->mask is noted down as orig_size, before proc_dointvec function get called. Then, proc_dointvec function read the interger value from the user buffer, which is then stored in a variable size.
This variable size is compared against the orig_size value, if size is not equal to orig_size, then new struct memory is allocated for rps_sock_flow_table. And then user entered size is stored in struct member rps_sock_flow_table->mask. rps_cpu_mask is updated, struct member rps_sock_flow_table->ents[] are filled with default entries (RPS_NO_CPU). When new rps_sock_flow_table is available, the original rps_sock_flow_table is replaced with this new struct. Finaly global variable rps_needed and rfs_needed is incremented.
Note: If the rps_needed, rfs_needed are already enabled and only the struct member rps_sock_flow_table->mask is updated, the rps_needed and rfs_needed count is decremented, so the features get enabled as before.
Writing into sys class entry rps_flow_cnt
static ssize_t store_rps_dev_flow_table_cnt(struct netdev_rx_queue *queue,
const char *buf, size_t len)
{
table = vmalloc(RPS_DEV_FLOW_TABLE_SIZE(mask + 1));
if (!table)
return -ENOMEM;
table->mask = mask;
for (count = 0; count <= mask; count++)
table->flows[count].cpu = RPS_NO_CPU;
} else {
table = NULL;
}
spin_lock(&rps_dev_flow_lock);
old_table = rcu_dereference_protected(queue->rps_flow_table,
lockdep_is_held(&rps_dev_flow_lock));
rcu_assign_pointer(queue->rps_flow_table, table);
spin_unlock(&rps_dev_flow_lock);
if (old_table)
call_rcu(&old_table->rcu, rps_dev_flow_table_release);
}In function store_rps_dev_flow_table_cnt, the size of the sys entry rps_flow_cnt is read, and sanity check is performed to avoid overflow. Then, memory is allocated for rps_dev_flow_table, so that the user entered rps_flow_cnt is being stored in struct member rps_dev_flow_table->mask. Also, for the size of the rps_flow_cnt the flow table rps_dev_flow_table->flows[rsp_flow_cnt].cpu is filled with RPS_NO_CPU.
At the end, pointer to this rps_dev_flow_table is assigned to netdev_rx_queue->rps_flow_table.
Feature implementation:
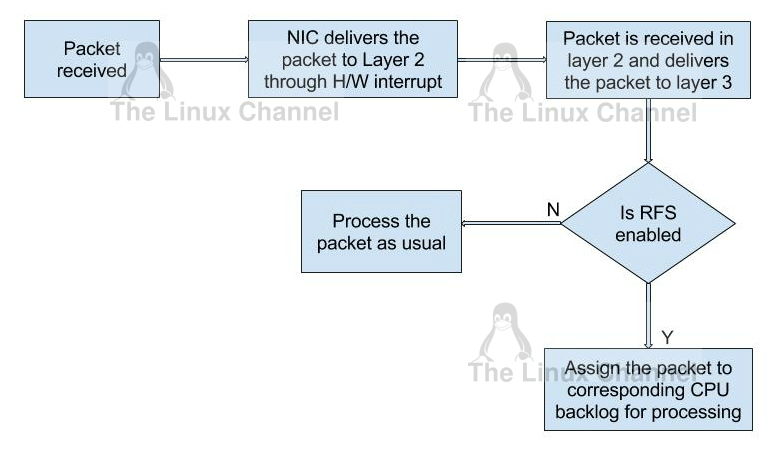
In RFS, packets are not forwarded directly by the value of their hash, but the hash is used as index into a flow lookup table. This table maps flows to the CPUs where those flows are being processed. The flow hash is used to calculate the index into this table. The CPU recorded in each entry is the one which last processed the flow. If an entry does not hold a valid CPU, then packets mapped to that entry are steered using plain RPS. Multiple table entries may point to the same CPU. Indeed, with many flows and few CPUs, it is very likely that a single application thread handles flows with many different flow hashes.
rps_sock_flow_table is a global flow table that contains the *desired* CPU for flows: the CPU that is currently processing the flow in userspace. Each table value is a CPU index that is updated during calls to recvmsg and sendmsg (specifically, inet_recvmsg(), inet_sendmsg(), inet_sendpage() and tcp_splice_read()).
For an instance, let us check the function inet_sendmsg.
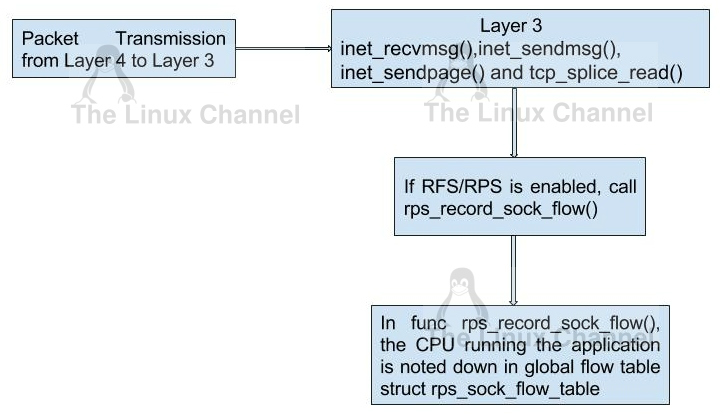
Refer Linux Kernel’s /net/ipv4/af_inet.c
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
sock_rps_record_flow(sk);
/* We may need to bind the socket. */
if (!inet_sk(sk)->inet_num && !sk->sk_prot->no_autobind &&
inet_autobind(sk))
return -EAGAIN;
return sk->sk_prot->sendmsg(sk, msg, size);
}
EXPORT_SYMBOL(inet_sendmsg);Refer Linux Kernel’s /include/linux/netdevice.h
static inline void rps_record_sock_flow(struct rps_sock_flow_table *table,
u32 hash)
{
if (table && hash) {
unsigned int index = hash & table->mask;
u32 val = hash & ~rps_cpu_mask;
/* We only give a hint, preemption can change CPU under us */
val |= raw_smp_processor_id();
if (table->ents[index] != val)
table->ents[index] = val;
}
}The heart of the function is rps_record_sock_flow, to which the global flow table rps_sock_flow_table and sk->rx_hash is passed as arguments. This function is get called when rfs_needed is enabled. Index of the flow table is computed using the struct member rps_sock_flow_table->mask and sk->rx_hash. The hash value is used as index into the global flow table and CPU in which the thread is running, is saved into this index value. This cpu is considered to be desired CPU upon packet reception.
When the scheduler moves a thread to a new CPU while it has outstanding receive packets on the old CPU, packets may arrive out of order. To avoid this, RFS uses a second flow table to track outstanding packets for each flow: rps_dev_flow_table is a table specific to each hardware receive queue of each device. Each table value stores a CPU index and a counter. The CPU index represents the current CPU onto which packets for this flow are enqueued for further kernel processing. Ideally, kernel and userspace processing occur on the same CPU, and hence the CPU index in both tables is identical. This is likely false if the scheduler has recently migrated a userspace thread while the kernel still has packets enqueued for kernel processing on the old CPU.
The counter in rps_dev_flow_table values records the length of the current CPU’s backlog when a packet in this flow was last enqueued. Each backlog queue has a head counter that is incremented on dequeue. A tail counter is computed as head counter + queue length. In other words, the counter in rps_dev_flow[i] records the last element in flow i that has been enqueued onto the currently designated CPU for flow i (of course, entry i is actually selected by hash and multiple flows may hash to the same entry i).
And now the trick for avoiding out of order packets: when selecting the CPU for packet processing (from get_rps_cpu()) the rps_sock_flow table and the rps_dev_flow table of the queue that the packet was received on are compared. If the desired CPU for the flow (found in the rps_sock_flow table) matches the current CPU (found in the rps_dev_flow table), the packet is enqueued onto that CPU’s backlog. If they differ, the current CPU is updated to match the desired CPU if one of the following is true:
- the current CPU’s queue head counter >= the recorded tail counter value in rps_dev_flow[i]
- the current CPU is unset (>= nr_cpu_ids)
- the current CPU is offline
After this check, the packet is sent to the (possibly updated) current CPU. These rules aim to ensure that a flow only moves to a new CPU when there are no packets outstanding on the old CPU, as the outstanding packet.
Let us check how this is accomplished in the code.
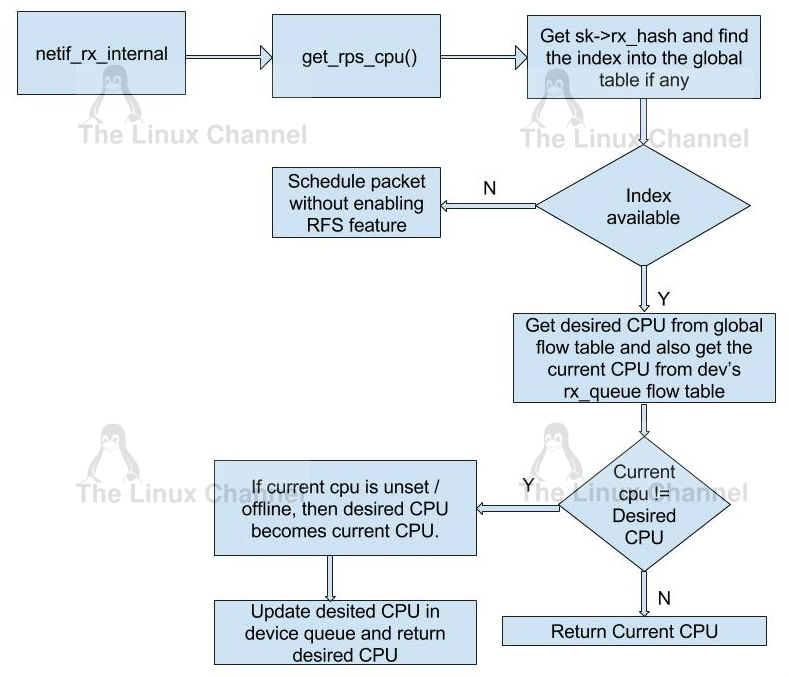
Refer Linux Kernel’s /net/core/dev.c
static int netif_rx_internal(struct sk_buff *skb)
{
...
...
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
...
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
...
}where get_rps_cpu() is in /net/core/dev.c
/*
* get_rps_cpu is called from netif_receive_skb and returns the target
* CPU from the RPS map of the receiving queue for a given skb.
* rcu_read_lock must be held on entry.
*/
static int get_rps_cpu(struct net_device *dev, struct sk_buff *skb,
struct rps_dev_flow **rflowp)
{
...
...
hash = skb_get_hash(skb);
if (!hash)
goto done;
sock_flow_table = rcu_dereference(rps_sock_flow_table);
if (flow_table && sock_flow_table) {
struct rps_dev_flow *rflow;
u32 next_cpu;
u32 ident;
/* First check into global flow table if there is a match */
ident = sock_flow_table->ents[hash & sock_flow_table->mask];
if ((ident ^ hash) & ~rps_cpu_mask)
goto try_rps;
next_cpu = ident & rps_cpu_mask;
/* OK, now we know there is a match,
* we can look at the local (per receive queue) flow table
*/
rflow = &flow_table->flows[hash & flow_table->mask];
tcpu = rflow->cpu;
/*
* If the desired CPU (where last recvmsg was done) is
* different from current CPU (one in the rx-queue flow
* table entry), switch if one of the following holds:
* - Current CPU is unset (>= nr_cpu_ids).
* - Current CPU is offline.
* - The current CPU's queue tail has advanced beyond the
* last packet that was enqueued using this table entry.
* This guarantees that all previous packets for the flow
* have been dequeued, thus preserving in order delivery.
*/
if (unlikely(tcpu != next_cpu) &&
(tcpu >= nr_cpu_ids || !cpu_online(tcpu) ||
((int)(per_cpu(softnet_data, tcpu).input_queue_head -
rflow->last_qtail)) >= 0)) {
tcpu = next_cpu;
rflow = set_rps_cpu(dev, skb, rflow, next_cpu);
}
if (tcpu < nr_cpu_ids && cpu_online(tcpu)) {
*rflowp = rflow;
cpu = tcpu;
goto done;
}
}
try_rps:
if (map) {
tcpu = map->cpus[reciprocal_scale(hash, map->len)];
if (cpu_online(tcpu)) {
cpu = tcpu;
goto done;
}
}
done:
return cpu;
}When packets are received in netif_rx_internal and if rfs_needed (or rps_needed are set together) is enabled, then the function get_rps_cpu() is get called. In function get_rps_cpu(), the global flow table rps_sock_flow_table (sock_flow_table) is dereferenced and also rps_dev_flow_table (flow_table) from netdev_rx_queue is dereferenced.
Using the hash value obtained from the netdev flow table, check whether same hash value is present in the global flow table. If there exists a index, then RFS is computed otherwise packets will be processed as if RFS is disabled. If hash value is present in global flow table, then cpu from netdev flow table is stored in tcpu. tcpu is considered as the current cpu whereas cpu from the global flow table is the desired cpu.
If desired cpu(next_cpu) is different from current cpu (tcpu), current cpu is overridden by desired cpu and then the cpu for the index in the rps_dev_flow_table is also overridden with the desired cpu in function set_rps_cpu().
Refer Linux Kernel’s /net/core/dev.c
static struct rps_dev_flow *
set_rps_cpu(struct net_device *dev, struct sk_buff *skb,
struct rps_dev_flow *rflow, u16 next_cpu)
{
...
...
rflow->last_qtail =
per_cpu(softnet_data, next_cpu).input_queue_head;
}
rflow->cpu = next_cpu;
...
}In function set_rps_cpu(), the length of the current CPU’s backlog when a packet in this flow was last enqueue is stored in struct member rflow->last_qtail.
Function get_rps_cpu() returns the cpu in which packets needs to be processed. This cpu value is then passed as an argument to function enqueue_to_backlog(). In function enqueue_to_backlog(), the received packet/skb instance is then queued into CPU backlog queue. Thus achieved increasing datacache hitrate of CPU.
Thus so far, we have seen how to enbale RFS feature and the implementation of RFS feature in the kernel. Let us see how RPS is enabled and implemented in near future.
Kindly refer: Linux Kernel documentation – Scaling in the Linux Networking Stack.